Work
Selected applied data science projects.
I approach applied data science problems by clarifying the decision problem, building a reproducible data workflow, choosing models that fit the data and use case, evaluating performance carefully, and translating results into recommendations.
Compliance Analytics
LLM validation for compliance review outputs
This Ropes & Gray project built a quality-control and validation system for structured compliance assessment outputs. The goal was not simply to generate text, but to evaluate whether analyst-written observations, recommendations, and scores were complete, internally consistent, category-appropriate, and supported by available evidence.
The pipeline combines deterministic preprocessing with LLM-based review. For each record, it dynamically assembles system instructions, injects category-specific rubrics, provides sampled peer observations from the same category, adds relevant structured context, and returns schema-constrained linting outputs that can be reviewed and audited.
- Dynamic prompts with category-specific rubrics and contextual evidence.
- Lightweight RAG-style calibration using sampled peer observations.
- Structured outputs for significant omissions, score concerns, and reviewer-facing critique.
Legal NLP
Legal text classification and law-coding automation
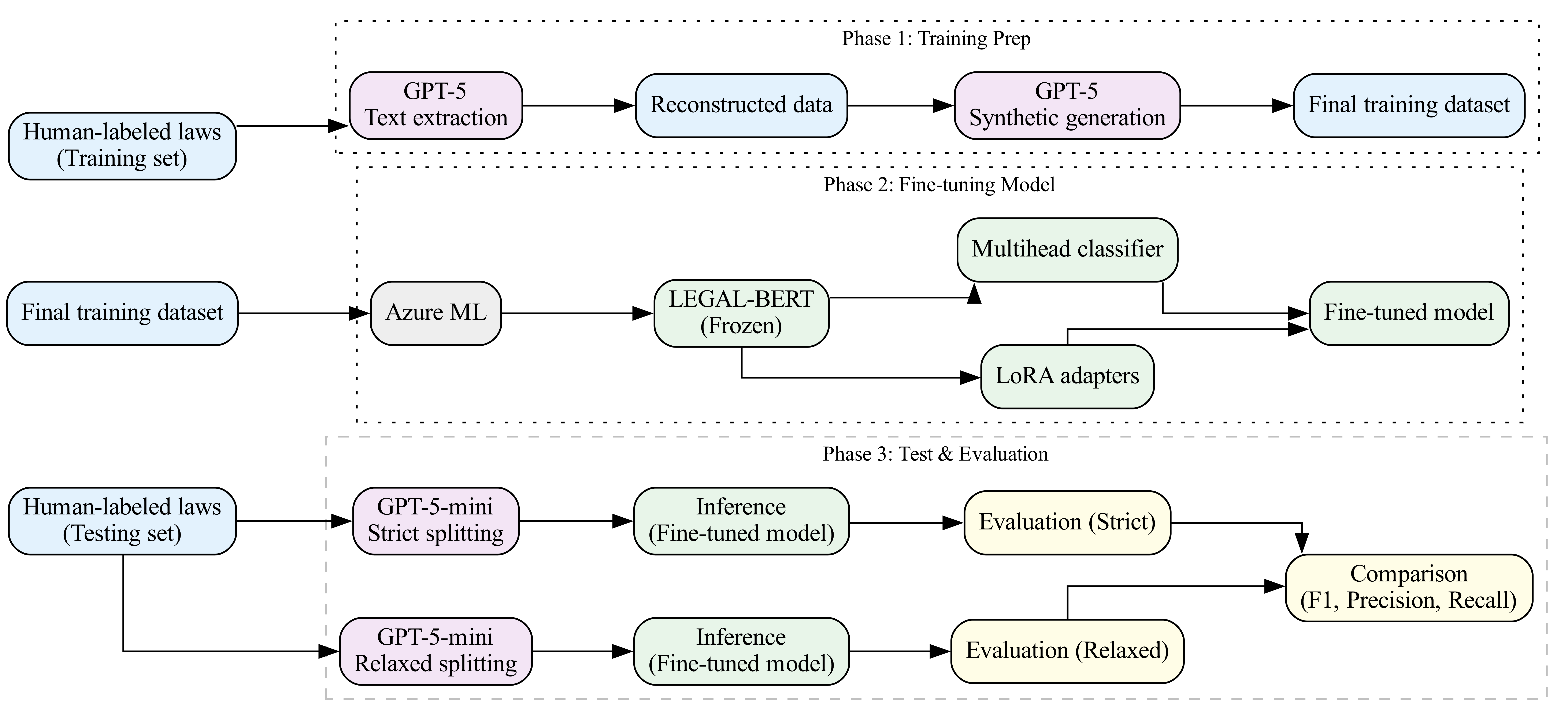
This Carter Center project tested ways to automate the coding of self-expression laws across a global legal corpus. The broader goal was to identify whether specific legal rules were included or explicitly excluded in each law.
I built a hybrid legal NLP pipeline that combined human-coded labels, GPT-assisted training-data reconstruction, synthetic data generation, Azure ML, and a fine-tuned LEGAL-BERT model. The workflow reconstructed provision-level training examples from human annotations, generated synthetic examples for sparse labels, and fine-tuned a legal-domain BERT model with LoRA adapters and a multihead classifier predicting both provision keys and deontic status.
- Used a 164-law corpus from 62 countries and 4 international organizations.
- Fine-tuned LEGAL-BERT with LoRA adapters and 1.67M trainable parameters.
- Evaluated predictions with F1, precision, and recall across exact and relaxed match criteria.
Program Evaluation
Sentiment analysis, geospatial features, and candidate behavior
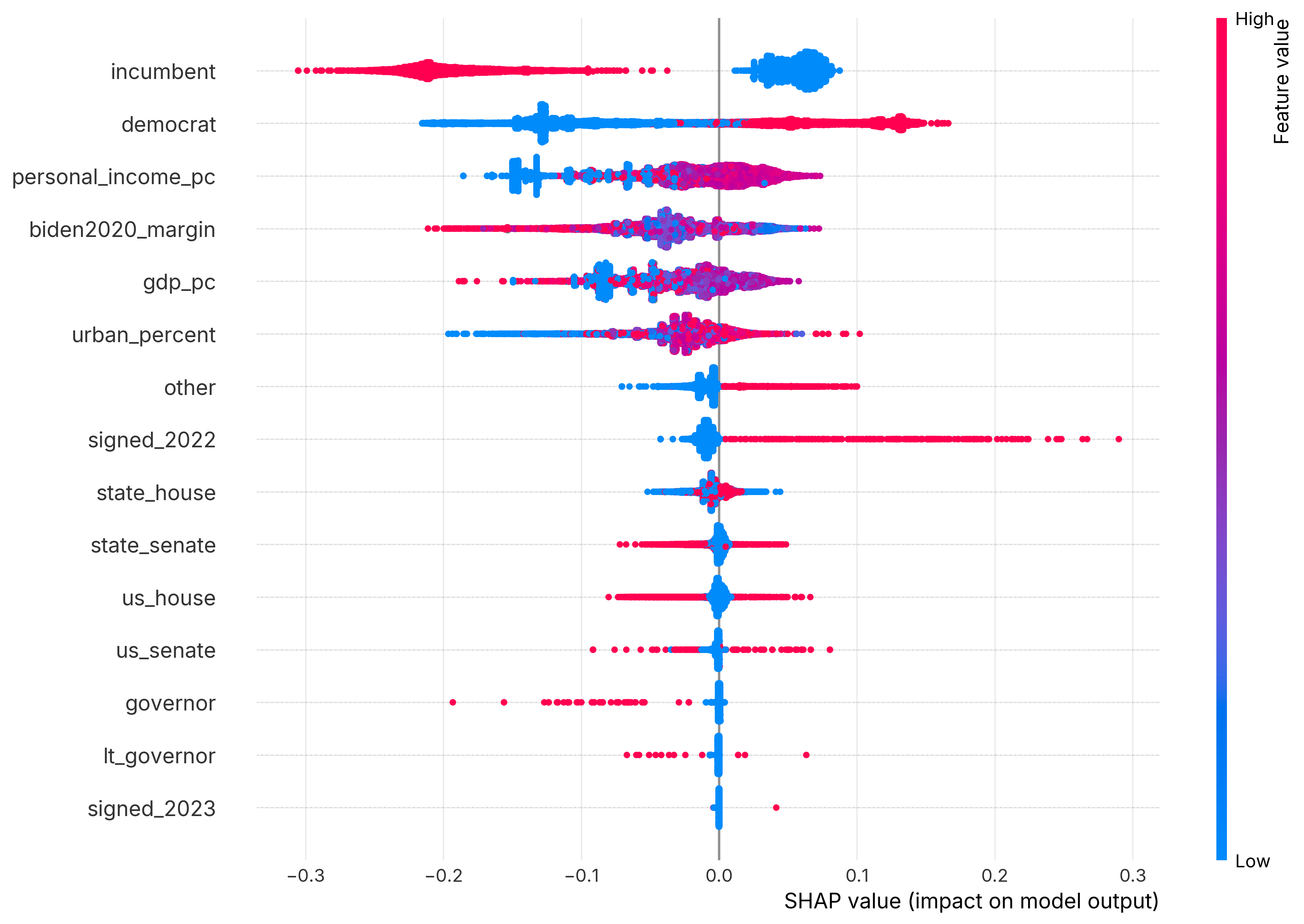
For The Carter Center, I designed and executed a quantitative evaluation of a high-profile political engagement program. The project asked two questions: which candidates were most likely to sign up, and whether candidates' social media posts became more or less supportive of the program's values after signing.
The work required linking program records, 2024 candidate data, vendor-provided social media records, district-level geospatial covariates, and roughly 1.15 million social media posts. Because the source data lacked a single common identifier, I used exact matching, fuzzy matching, custom cleaning functions, and extensive validation checks.
- Compared logistic regression and random forest models for candidate sign-up.
- Used feature importance and SHAP values to interpret model behavior.
- Built a custom dictionary-based sentiment measure after VADER proved too general.
Risk and Due Diligence
Risk-score validation from written due diligence reviews
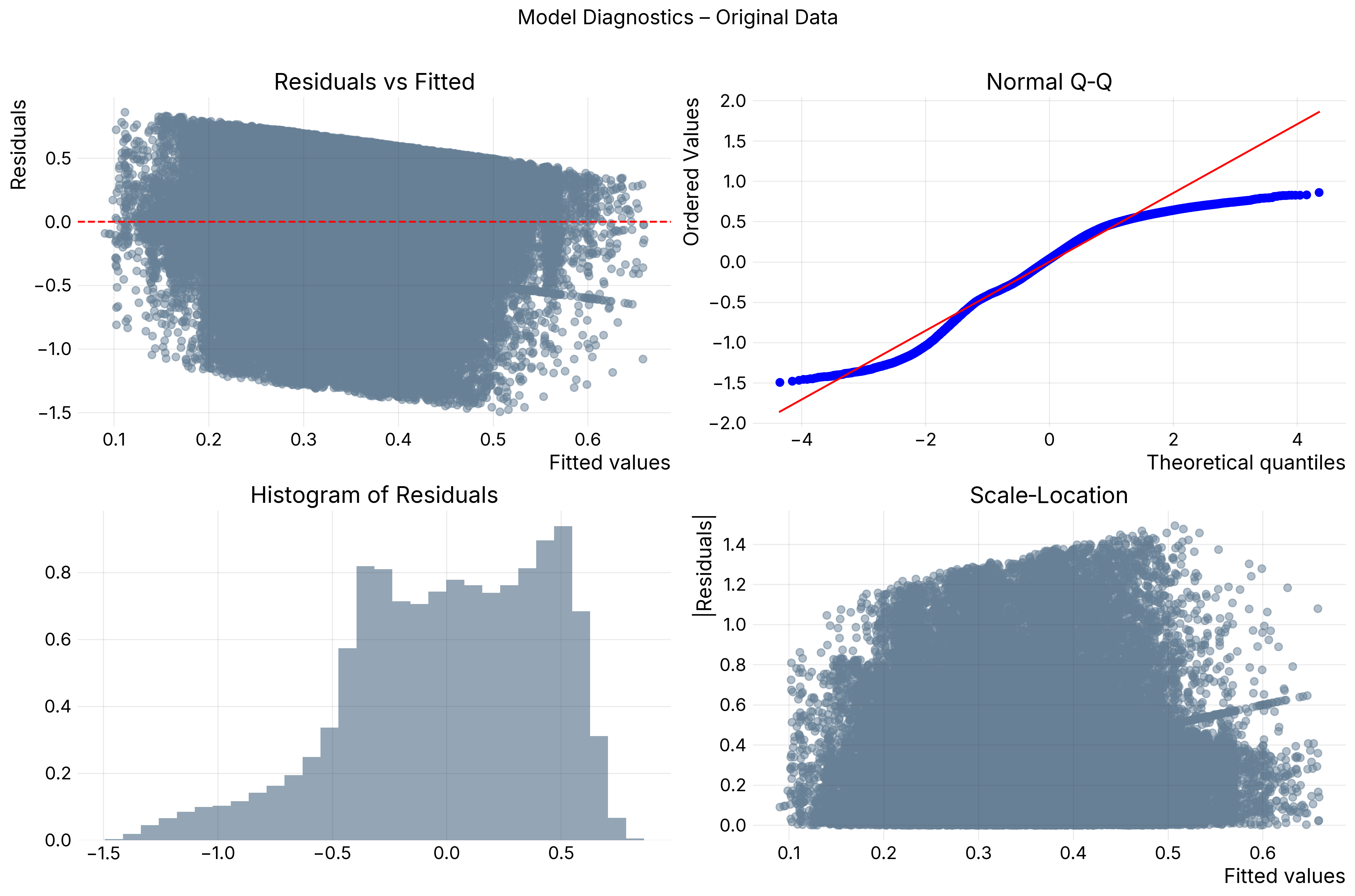
This project evaluated whether written risk and due diligence justifications consistently mapped to similar risk scores. The core question was whether similar text chunks clustered together with the same or similar scores.
The workflow loaded semi-structured JSON records, aligned scores and text across inconsistent date fields, embedded written justifications, and compared HDBSCAN, KMeans, and spectral clustering. I then used Kruskal-Wallis tests, cosine-distance heatmaps, PCA, qualitative review, token-level feature engineering, ElasticNet feature selection, and ordinal models to interpret text-score alignment.
- Reduced 1,536-dimensional embeddings to 245 principal components while preserving 90% of variation.
- Compared score distributions across category-level embedding clusters.
- Produced analysis that motivated follow-on compliance analytics tool concepts.
Conflict Prediction
Predicting civil war interventions
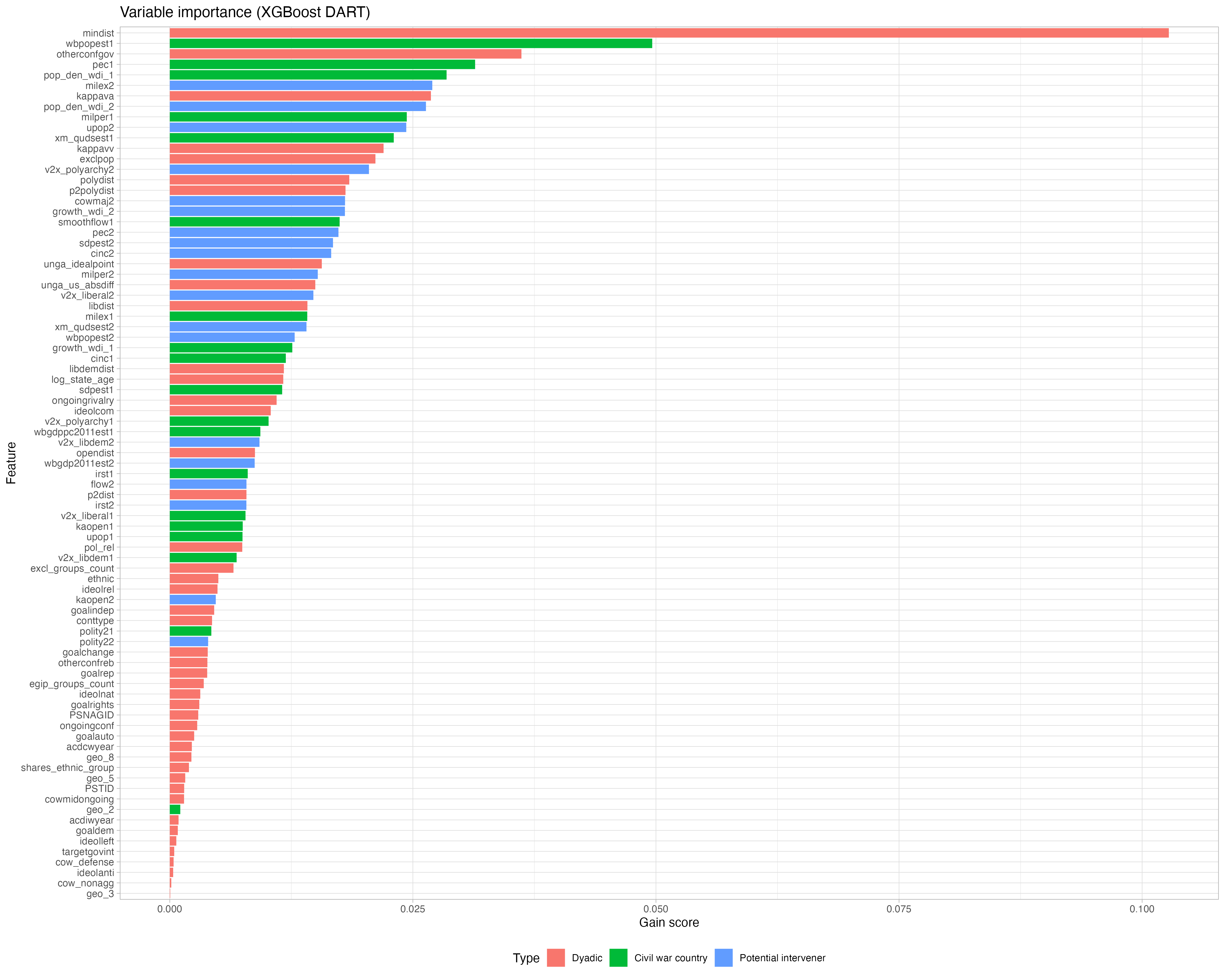
This project builds multiclass machine-learning models to predict whether a third-party state will stay out of a civil war, support the government, or support rebel forces. The dataset treats every other state in the international system as a potential intervener in each civil war, producing 34,552 dyadic observations.
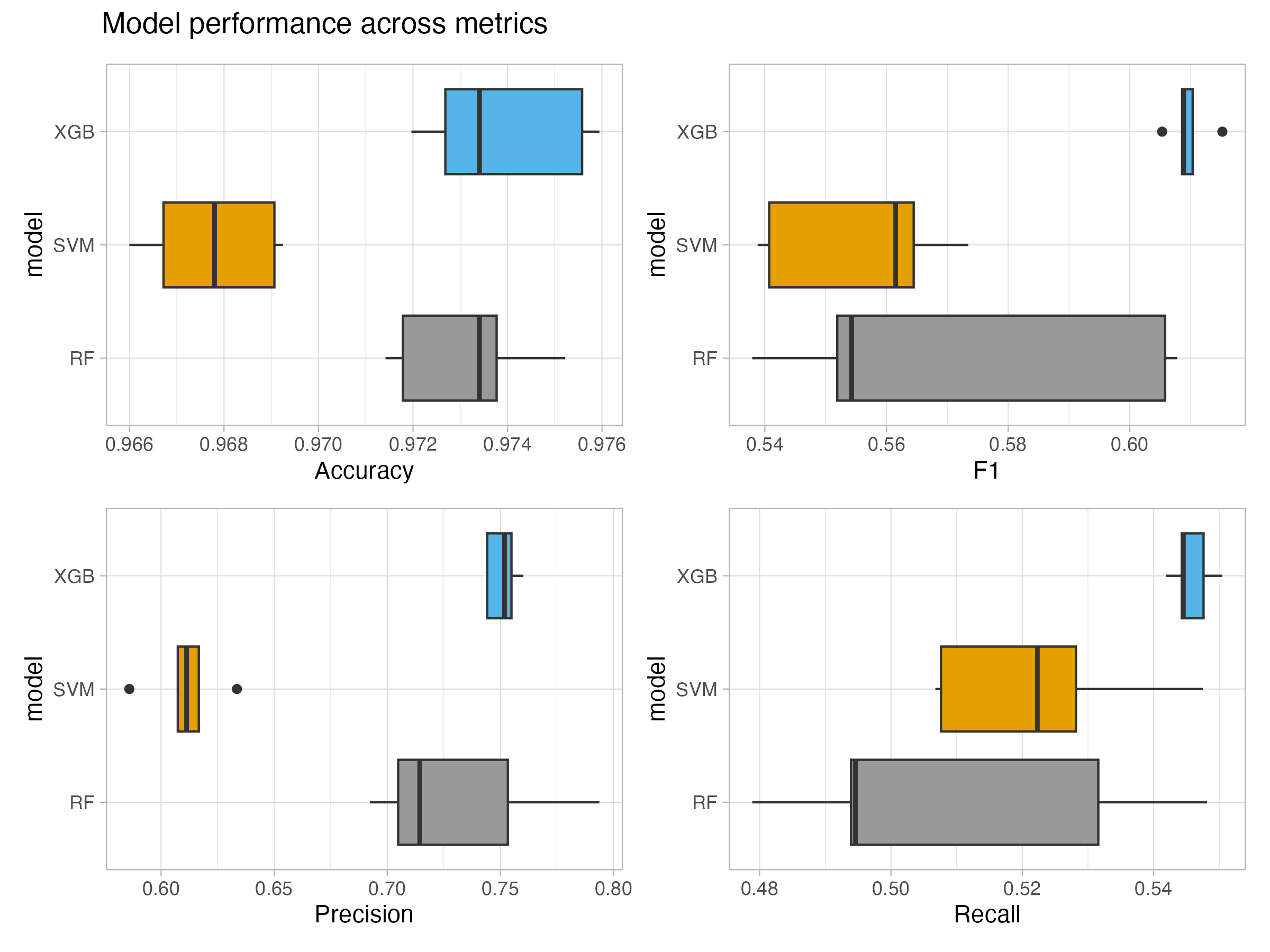
I began with multinomial logistic regression benchmarks and theory-driven feature engineering, including measures of political, ideological, economic, and foreign-policy distance between states. I then trained and tuned random forest, support vector machine, and XGBoost DART models using preprocessing, recursive feature elimination, elastic net, five-fold cross-validation, diagnostic review, and variable-importance analysis.
- Modeled a rare, imbalanced multiclass outcome with 34,552 observations.
- Improved mean F1 from a 0.37 benchmark to 0.609 in the optimized model.
- Used model diagnostics and domain knowledge to refine features and interpret findings.